Indhold:
At forstå datastrømme
At læse og skrive filer
At analysere tekstfiler og udtrække data
Overblikket over og sammenhængen mellem alle datastrøm-klasserne
Kapitlet forudsættes af kapitel 16, Netværkskommunikation og 18, Serialisering.
Forudsætter kapitel 14, Undtagelser.
En fil er et arkiv på et lagermedium, hvori der er gemt data. På lagermediet gemmes en række 0'er og 1-taller (bit) i grupper á 8 bit, svarende til en byte (et tal mellem 0 og 255).
Data kan være gemt binært, sådan at de kun kan læses af et program eller styresystemet. Det gælder f.eks. en .exe-fil eller et dokument gemt i et proprietært binært format som f.eks. Word. De kan også være gemt som tekst uden formatering. Det gælder f.eks. filer, der ender på .txt, .html og .java. Oplysningerne i tekstfiler kan læses med en teksteditor1. Det er op til programmet, der læser/skriver i filen at afgøre, om indholdet er tekst eller binært.
I Java behandles filer som datastrømme. En datastrøm er et objekt, som man enten henter data fra (læser fra en datakilde, f.eks. en fil) eller2 skriver data til (et datamål).
Denne arbejdsmåde gør, at forskellige datakilder og -mål kan behandles ensartet, og at det er let at udskifte datakilden eller -målet med noget andet end en fil, f.eks. en forbindelse til netværket.
Klassen FileWriter bruges til at skrive en fil med tekstdata. I konstruktøren angiver man filnavnet:
FileWriter fil = new FileWriter("tekstfil.txt");FileWriter-objektet er en datastrøm, hvis mål er filen. Nu kan man skrive tekstdata til filen med:
fil.write("Her kommer et tal:\n");
fil.write(322+"\n");FileWriter-objektets write()-metode er lidt besværlig at arbejde med, da den ikke understøtter linieskift (som så i stedet må laves med "\n").
Det er mere bekvemt at lægge objektet ind i en PrintWriter. Et PrintWriter-objekt har print() og println()-metoder, som vi er vant til, og man skal skrive til den præcis, som når man skriver til System.out:
PrintWriter ud = new PrintWriter(fil);
ud.println("Her kommer et tal:");
ud.println(322);Når vi skriver til PrintWriter-objektet, sender det teksten videre til FileWriter-objektet, der skriver teksten i filen.
Det er vigtigt at lukke filen, når man er færdig med at skrive. Ellers kan de sidste data gå tabt! Det gør man ved at lukke datastrømmen, man skrev til:
ud.close();
Her er et samlet eksempel, der skriver nogle fiktive personers navn, køn og alder til en fil:
import java.io.*;
public class SkrivTekstfil
{
public static void main(String[] arg) throws IOException
{
FileWriter fil = new FileWriter("skrevet fil.txt");
PrintWriter ud = new PrintWriter(fil);
for (int i=0; i<5; i++)
{
String navn = "person"+i;
String køn;
if (Math.random()>0.5) køn = "m"; else køn = "k";
int alder = 10+(int) (Math.random()*60);
ud.println(navn+" "+køn+" "+alder);
}
ud.close(); // luk så alle data skrives til disken
System.out.println("Filen er gemt.");
}
}
Filen er gemt.
Eventuelle IO-undtagelser (f.eks. ikke mere plads på disken) tager vi os ikke af, men sender dem videre til styresystemet (main()-metoden er erklæret som "throws IOException").
Efter at programmet har kørt, findes filen "skrevet fil.txt" på disken, med indhold:
person0 m 34 person1 m 26 person2 m 24 person3 k 51 person4 k 16
Lad os læse filen ovenfor og skrive den ud til skærmen.
Til det formål bruger vi et FileReader-objekt som datakilde. Igen pakker vi det ind i et andet objekt, denne gang af klassen BufferedReader. BufferedReader gør det mere bekvemt, da indlæsning kan ske linie for linie med metoden readLine(). Når der ikke er flere data, returnerer readLine() null.
import java.io.*;
import java.util.*;
public class LaesTekstfil
{
public static void main(String[] arg) throws IOException
{
FileReader fil = new FileReader("skrevet fil.txt");
BufferedReader ind = new BufferedReader(fil);
String linie = ind.readLine();
while (linie != null)
{
System.out.println("Læst: "+linie);
linie = ind.readLine();
}
}
}
Læst: person0 m 34 Læst: person1 m 26 Læst: person2 m 24 Læst: person3 k 51 Læst: person4 k 16
For et tekstbaseret (ikke-grafisk) program skal uddata som bekendt skrives til System.out.
Det modsvarende objekt til at læse fra tastaturet, System.in, er en byte-baseret (binær) datastrøm. Det er nemmest at pakke den ind i en InputStreamReader, der konverterer binær til tegnbaseret tekstindlæsning
InputStreamReader tegnlæser = new InputStreamReader(System.in);
... og derpå gøre den linieorienteret ved at pakke den yderligere ind i et BufferedReader-objekt:
BufferedReader ind = new BufferedReader( tegnlæser );
Derefter kan man læse inddata fra tastaturet linie for linie, ligesom vi gør med filer:
String linie = ind.readLine();
Der er et eksempel på dette i afsnit 14.3.2.
Ofte er det ikke nok bare at indlæse data, de skal også kunne behandles bagefter.
For eksempel kunne det være sjovt at udregne aldersgennemsnittet i LaesTekstfil.java. Det kræver, at vi først opdeler data i bidder (med StringTokenizer, se afsnit 3.9.5 og 3.6.2) for at finde kolonnen med aldrene og derefter konverterer dem til tal, der kan regnes på.
For at omsætte en streng til et tal (int eller double) skal strengen analyseres (eng.: parse), dvs. undersøges for, om den indeholder et tal, og tallet, som kan være repræsenteret på mange måder, skal findes frem.
Det har Integer- og Double-klasserne funktioner til3, nemlig hhv. parseInt() og parseDouble(). De får en streng som parameter og returnerer den ønskede type:
int i = Integer.parseInt("542");
double d = Double.parseDouble("3.14");
Eksponentiel notation (hvor 9.8E3 betyder 9800) forstås også, og der kan også bruges andre talsystemer end titalsystemet. F.eks. giver Integer.parseInt("00010011",2) tallet 19 (19 svarer til 00010011 i det binære talsystem), og Integer.parseInt("1F",16) giver 31 (1F i det hexadecimale talsystem):
d = Double.parseDouble("9.8E3"); // d = 9800
i = Integer.parseInt("00010011",2); // i = 19
i = Integer.parseInt("1F",16); // i = 31
En anden mulighed er at benytte klassen DecimalFormat, der giver mulighed for at formatere og analysere strenge for forskellige talformater. Den er beskrevet i afsnit 3.10.3.
Lad os lave et statistikprogram. Vi tæller antallet af personer (linier i filen) og summen af aldrene. Linierne analyseres og lægges ind i variablerne navn, køn og alder.
import java.io.*;
import java.util.*;
public class LaesTekstfilOgLavStatistik
{
public static void main(String[] arg)
{
int antalPersoner = 0;
int sumAlder = 0;
try
{
BufferedReader ind =
new BufferedReader(new FileReader("skrevet fil.txt"));
String linie = ind.readLine();
while (linie != null)
{
try
{
StringTokenizer bidder = new StringTokenizer(linie);
String navn = bidder.nextToken();
String køn = bidder.nextToken();
int alder = Integer.parseInt(bidder.nextToken());
System.out.println(navn+" er "+alder+" år.");
antalPersoner = antalPersoner + 1;
sumAlder = sumAlder + alder;
} catch (Exception u)
{
System.out.println("Fejl. Linien springes over.");
u.printStackTrace();
}
linie = ind.readLine();
}
System.out.println("Aldersgennemsnittet er: "+sumAlder/antalPersoner);
} catch (FileNotFoundException u)
{
System.out.println("Filen kunne ikke findes.");
} catch (Exception u)
{
System.out.println("Fejl ved læsning af fil.");
u.printStackTrace();
}
}
}
person0 er 34 år. person1 er 26 år. person2 er 24 år. person3 er 51 år. person4 er 16 år. Aldersgennemsnittet er: 30
Undervejs kan der opstå forskellige undtagelser. Hvis filen ikke eksisterer, udskrives "Filen kunne ikke findes", og programmet afslutter. En anden mulig fejl er, at filen er tom. Så vil der opstå en aritmetisk undtagelse (division med nul), når vi dividerer med antalPersoner, og "Fejl ved læsning af fil" udskrives.
Under analyseringen af linien kan der også opstå flere slags undtagelser: Konverteringen til heltal kan gå galt, og der kan være for få bidder, så nextToken() bliver kaldt efter sidste bid.
For eksempel giver linien "person2 m24" (der mangler et mellemrum mellem m og 24)
Fejl. Linien springes over.
java.util.NoSuchElementException
at java.util.StringTokenizer.nextToken(StringTokenizer.java:241)
at LaesTekstfil.main(LaesTekstfil.java:25)Hvis disse fejl opstår, fortsætter programmet efter catch-blokken med at læse næste linie af inddata. Da sumAlder og antalPersoner ændres sidst i try-catch-blokken, vil de kun blive opdateret, hvis hele linien er i orden, og statistikken udregnes derfor kun på grundlag af de gyldige linier.
Arbejder man med binære data (f.eks lyd- eller billedfiler), skal det ske binært. En anden grund til at arbejde med binære data er, at oversættelsen fra binære til tekstdata tager tid.
Det følgende eksempel kopierer en fil (bog.html) binært til en anden fil:
import java.io.*;
public class KopierFil
{
public static void main(String[] arg) throws IOException
{
InputStream is = new FileInputStream("bog.html");
OutputStream os = new FileOutputStream("kopieretBog.html");
// brug buffere i læsning og skrivning (mere effektivt) punkt A
// kommenteret ud: is = new BufferedInputStream(is);
// kommenteret ud: os = new BufferedOutputStream(os);
// husk starttidpunkt, så vi kan måle hvor lang tid det teger
long starttid = System.currentTimeMillis();
// læs og skriv én byte ad gangen (ret ineffektivt) punkt B
int b = is.read();
while (b != -1)
{
os.write(b);
b = is.read();
}
is.close();
os.close();
long sluttid = System.currentTimeMillis();
System.out.println("Kopiering tog "+ (sluttid-starttid)*0.001 +" sek.");
}
}
Kopiering tog 4.713 sek.
Programmet, som det umiddelbart ser ud (punkt A er kommenteret ud), udfører opgaven ved at læse én byte fra filen, skrive den til den anden fil, læse en ny byte o.s.v. Det går ret langsomt, filen bog.html, der fylder ca. 100 kb, tager knap fem sekunder at kopiere.
Her udføres programmet igen, med punkt A kommenteret ind, så der bruges buffere til læsning og skrivning. Programmet udskriver da:
Kopiering tog 0.089 sek.
Vi opnår altså en hastighedsforøgelse på over en faktor halvtreds (!) ved at bruge buffere. Bufferne tager højde for vores en-byte-ad-gangen-kopiering og bevirker, at læsning og skrivning sker i klumper á et par kilobyte, hvilket er langt mere effektivt.
Vi kunne også selv sørge for, at data bliver læst i større klumper, ved at bruge et array (beskrevet i kapitel 8). Erstatter vi punkt B med det følgende, går det endnu hurtigere:
// læs og skriv i større klumper (mere effektivt)
byte[] data = new byte[4096]; // 4 kilobyte
int lgd = is.read(data);
while (lgd != -1)
{
os.write(data, 0, lgd);
lgd = is.read(data);
}
Kopiering tog 0.0060 sek.
Denne tid (75 gange hurtigere) er uafhængig af, om der bruges buffere eller ej (i punkt A).
Brug buffere, eller sørg for, at dit program behandler data i større klumper
I pakken java.io findes omkring 40 klasser, der kan læse eller skrive binære eller tegnbaserede data fra et væld af datakilder eller -mål og på et væld af forskellige måder. Der henvises til javadokumentationen for en nærmere beskrivelse af de enkelte klasser.
Næsten alle metoderne i klasserne kan kaste en IOException-undtagelse, som skal fanges i en try-catch-blok (eller kastes videre som beskrevet i kapitlet om undtagelser).
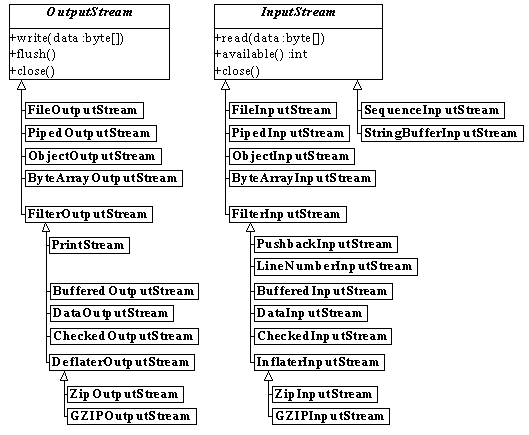
Datastrømmene kan ordnes i fire grupper, og den konsistente navngivning gør dem lettere at overskue:
InputStream-objekter læser binære data. OutputStream-objekter skriver binære data.
Reader-objekter læser tekstdata. Writer-objekter skriver tekstdata.
Byte-baserede data som f.eks. billeder, lyde eller andre binære programdata håndteres af klasser, der arver fra InputStream eller OutputStream.
Af klassediagrammet ses, at metoderne i InputStream og OutputStream læser og skriver byte-data: write(byte[]) på OutputStream skriver et array (en række) af byte. Arvingerne har lignende metoder (disse er ikke vist).
InputStream og OutputStream er tegnet i kursiv. Det er fordi de er abstrakte klasser, og det betyder, at man ikke kan oprette InputStream og OutputStream-objekter direkte med f.eks. new InputStream(). I stedet skal man bruge en af nedarvingerne. Abstrakte klasser bliver behandlet i kapitel 21, Avancerede klasser.
Tegn-baserede data bruges til tekstfiler, til at læse brugerinput og til meget netværkskommunikation. Dette håndteres af klasserne, der nedarver fra Reader og Writer.
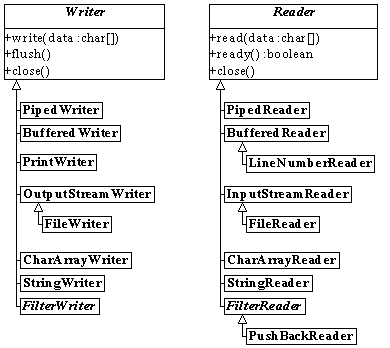
Af klassediagrammet ses, at alle metoderne i Reader og Writer læser og skriver tegndata (datatype char). Tegn repræsenteres i Java som 16-bit unikode-værdier, og man kan derfor arbejde med ikke blot det vesteuropæiske tegnsæt, men også det østeuropæiske, kinesiske, russiske, ...
Klasserne til filhåndtering er FileInputStream, FileReader, FileOutputStream og FileWriter.
Med StringReader kan man læse data fra en streng, som om det kom fra en datastrøm. Det kan være praktisk til f.eks. at simulere indtastninger fra tastaturet under test (sml. afsnit 15.3, Indlæsning fra tastatur).
StringReader tegnlæser = new StringReader("Jacob\n4\n5.14\n");
BufferedReader ind = new BufferedReader( tegnlæser );StringWriter er en datastrøm, der gemmer uddata i et StringBuffer-objekt, der kan konverteres til en streng.
Et array er en liste eller række af noget (se kapitel 8). Ligesom man kan behandle en streng som en datastrøm, kan man også arbejde med et array som datakilde eller -mål. Klasserne CharArrayReader og CharArrayWriter hhv. læser og skriver fra et array af tegn, mens ByteArrayInputStream og ByteArrayOutputStream læser og skriver binært i et array af byte.
Det er muligt at skrive hele objekter ned i en datastrøm med ObjectOutputStream. Objekterne bliver da "serialiseret", dvs. dets data gemmes i datastrømmen. Refererer objektet til andre objekter, bliver disse også serialiseret og så fremdeles. Dette er nyttigt til at gemme en hel graf af objekter på disken for senere at hente den frem igen. Emnet vil blive behandlet mere i kapitel 18, Serialisering.
Klasserne BufferedInputStream, BufferedReader, BufferedOutputStream og BufferedWriter sørger for en buffer (et opsamlingsområde) til datastrømmen. Det sikrer mere effektiv indlæsning, fordi der bliver læst/skrevet større blokke data ad gangen.
BufferedReader sørger også for, at man kan læse en hel linie af datastrømmen ad gangen.
Nogen gange står man med en binær datastrøm og ønsker at arbejde med den, som om den var tekstbaseret. Der er to klasser, der konverterer til tegnbaseret indlæsning og -udlæsning:
InputStreamReader er et Reader-objekt, der læser fra en InputStream (byte til tegn).
OutputStreamWriter er et Writer-objekt, der skriver til en OutputStream (tegn til byte).
Klasserne, der arver fra FilterOutputStream og FilterInputStream, sørger alle for en eller anden form for behandling og præsentation, der letter programmørens arbejde:
LineNumber-klasser tæller antallet af linieskift i datastrømmen, men lader den ellers være uændret.
Pushback-klasser giver mulighed for at skubbe data tilbage i datastrømmen (nyttigt, hvis man af en eller anden grund kan "komme til" at læse for langt).
SequenceInputStream sætter to eller flere datakilder i forlængelse af hinanden.
Piped-klasserne letter datakommunikationen mellem to tråde (samtidige programudførelsespunkter i et program) ved at sætte data "i kø" sådan, at en tråd kan læse fra datastrømmen og en anden skrive.
Checked-klasserne (i pakken java.util.zip) udregner en checksum på data. Det kan være nyttigt til at undersøge, om nogen eller noget har ændret data (f.eks. en cracker eller en dårlig diskette). Man skal angive et checksum-objekt, f.eks. Adler32 eller CRC32.
Zip-klasserne (i java.util.zip) læser og skriver zip-filer (lavet af f.eks. WinZip). De er lidt indviklede at bruge, da de er indrettet til at håndtere pakning af flere filer.
GZIP-klasserne (i java.util.zip) komprimerer og dekomprimerer data med Lempel-Ziv-kompression, kendt fra filer, der ender på .gz på UNIX-systemer (især Linux). Er nemmere at bruge end Zip-klasserne, hvis man kun ønsker at pakke én fil.
Filtreringsklasser skydes ind som ekstra "indpakning" mellem de andre datastrømme. F.eks. kan
PrintWriter ud = new PrintWriter( new FileOutputStream("fil.txt"));ændres til også at komprimere uddata, simpelthen ved at skyde et GZIPOutputStream-objekt ind:
PrintWriter ud = new PrintWriter( new GZIPOutputStream(
new FileOutputStream("fil.txt.gz"));
Herunder læser vi en fil og udregner filens checksum og antallet af linier i filen.
import java.io.*;
import java.util.zip.*;
public class UndersoegFil
{
public static void main(String[] arg) throws IOException
{
FileInputStream fil = new FileInputStream("skrevet fil.txt");
BufferedInputStream bstrøm = new BufferedInputStream(fil);
CRC32 checksum = new CRC32();
CheckedInputStream chkstrøm = new CheckedInputStream(bstrøm,checksum);
InputStreamReader txtstrøm = new InputStreamReader(chkstrøm);
LineNumberReader ind = new LineNumberReader(txtstrøm);
String linie;
while ((linie=ind.readLine())!= null) System.out.println("Læst: "+linie);
System.out.println("Antal linier: " +ind.getLineNumber());
System.out.println("Checksum (CRC):" +checksum.getValue());
}
}
Læst: person0 k 43 Læst: person1 k 10 Læst: person2 k 16 Læst: person3 k 11 Læst: person4 k 21 Antal linier: 5 Checksum (CRC):3543848051
Læg mærke til, hvordan vi hægter datastrøm-objekterne sammen i en kæde ved hele tiden at bruge det forrige objekt som parameter til konstruktørerne: Filindlæsning, buffering, checksum, gå fra binær til tekstbaseret indlæsning (InputStreamReader) og linietælling.
While-løkken er skrevet meget kompakt med en tildeling (linie=ind.readLine()) og derefter en sammenligning, om værdien af tildelingen var null ( (..) != null).
Prøv eksemplerne fra kapitlet og:
Udvid LaesTekstfilOgLavStatistik.java sådan, at linier, der starter med "#", er kommentarer, som ignoreres, og afprøv, om programmet virker.
Lav et program, der læser fra en
tekstfil, skyld.txt, og udskriver summen af tallene i hver linie med
navnet foranstillet (f.eks. Anne: 450).
Filen kunne f.eks. indeholde:
Anne 300
150
Peter 18 300 900 -950
Lis 1000 13.5
Skriv programmet Grep.java, der læser en fil og udskriver alle linier, der indeholder en bestemt delstreng (vink: Ret LaesTekstfil.java - en linie undersøges for en delstreng med substring(...)).
Skriv programmet Diff.java, der sammenligner to tekstfiler linie for linie og udskriver de linier, der er forskellige.
Ret SkrivTekstfil.java til SkrivKomprimeretTekstfil.java, der gemmer data komprimeret med GZIPOutputStream (se appendiks).
Lav den tilsvarende LaesKomprimeretTekstfilOgLavStatistik.java.
Kør KopierFil på din maskine, og
se, hvor lang tid det tager (husk at lægge en fil med navn
bog.html på ca. 100 kb det rette sted, eller ret filnavnet i
programmet).
Prøv derefter, hvor du bruger buffere for
mere effektiv læsning og skrivning.
Prøv igen, hvor
programmet læser og skriver 4 kb ad gangen.
Gør det
nu nogen forskel, om du bruger buffere? Hvorfor/hvorfor ikke?
1Teksten kan dog stadig være kryptisk og uforståelig, som f.eks. .java-kildetekst er for en udenforstående.
2Det er dog muligt at åbne en fil for samtidig læsning og skrivning med klassen RandomAccessFile, beskrevet i Javadokumentationen.
3Dette
er de oftest brugte, men tilsvarende findes Byte.parseByte(),
Long.parseLong(), Float.parseFloat() osv. Nogle af metoderne kom
først til i JDK version 1.2. I f.eks appletter, der bruger
JDK 1.1.7, eller tidligere kan det være nødvendigt at
oprette objekter, f.eks.
int i = new Integer("542").intValue();